关于东方财富的逐笔还原数据 东方财富手机 APP 端有一个逐笔还原功能, 一般在东方财富月均资产在 1w 以上可以免费领取 Level 2 分时成交明细和 十档盘口与千档盘口, 不同的交易标的对应不同的盘口数量. 同时除了逐笔还原数据外, 还有买一和卖一的 全息队列, 交易分布 和 逐笔委托 数据. 现在对逐笔还原数据和分时成交数据进行比较. 为了能看明白其中的原理, 这里选一个交易不那么活跃的来进行分析.
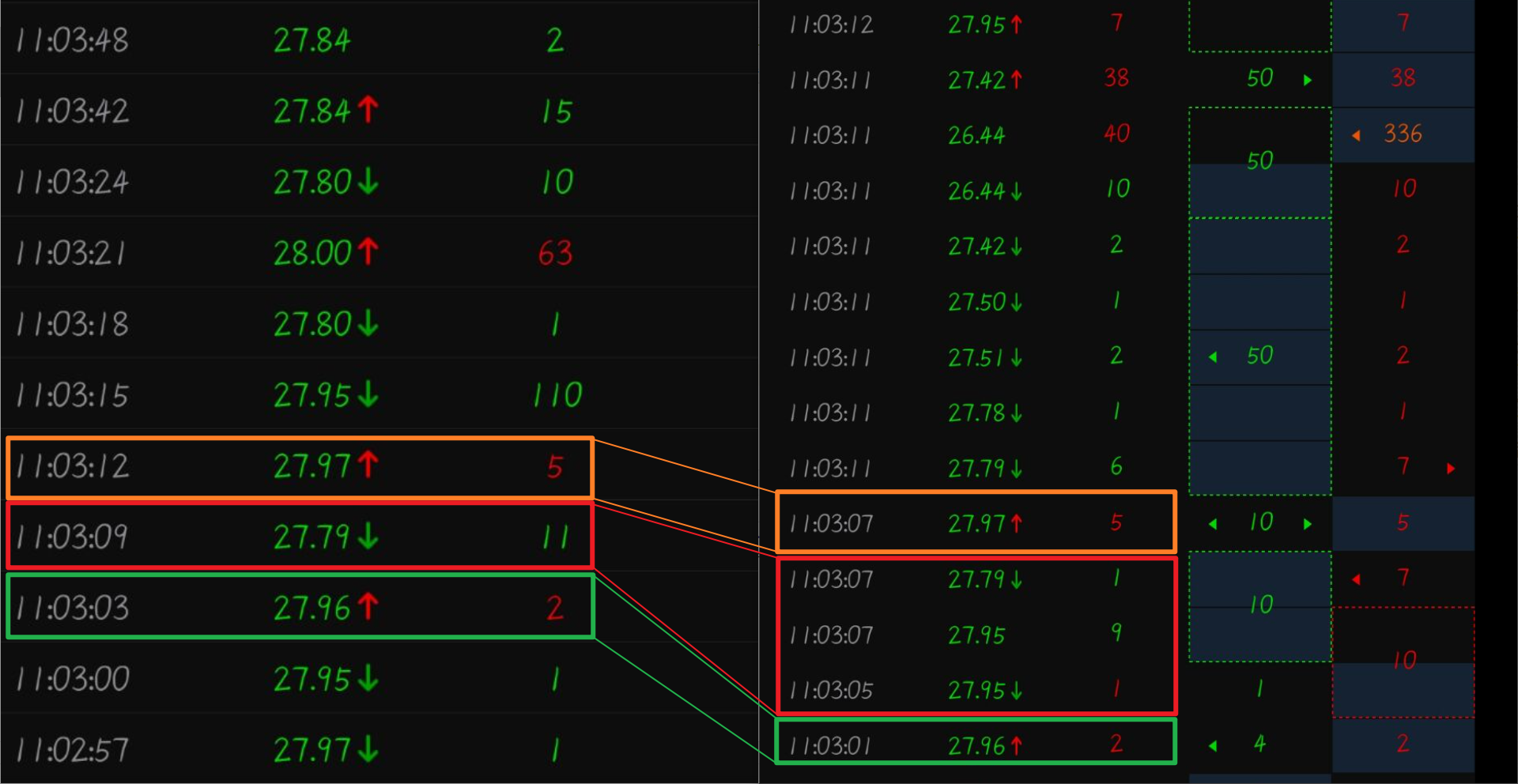
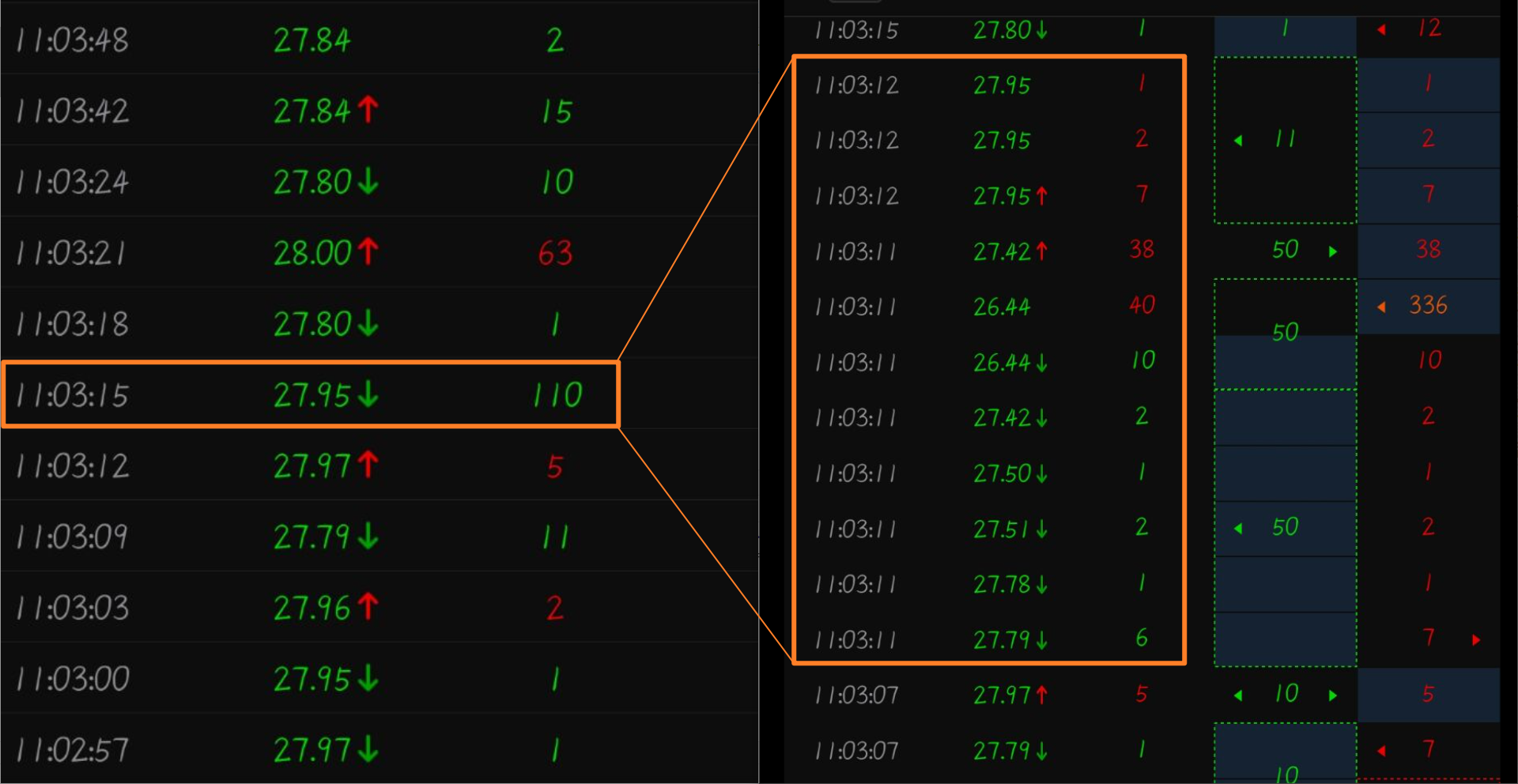
11:05 分为主动卖出交易, 从逐笔还原来看, 交易委卖价格 16.91 是 盘口的买一价, 为主卖立即成交. 而从逐笔还原的买单列并结合超级复盘的盘口看, 这 12 手卖单是由 10手中剩余的 1 手, 5 个 1 手和 154 手中的 6 手组成. 其中逐笔还原图中 154 手处向左的箭头表示之后还有撮合. 这个 154 手是合计了之后的撮合成交的手数之和, 最后一笔撮合的 154 手会显示向右的箭头, 中间的撮合部分左右箭头都显示, 在这笔成交中只有 6 手, 154 手的委托买一手数可能更大, 只是撮合成交了 154 手而已. 对于主动买入的逐笔交易还原也是类似的.
一种交易方式: 从逐笔还原来看, 很难看出主力的意图, 买卖的单子可能都是主力挂的, 有些挂单可以被撤掉. 比如在卖一挂出 1w 手委卖单, 然后以买一价逐笔买入, 如果卖一是分笔挂单的, 又可以逐笔撤去未成交的挂单. 这可以用于伪造成交量和委比. (交易大户的交易手续费比散户的更低, 忽略不计.)
需要注意的是, 因为分时成交数据是逐笔还原中的数据每隔 3 秒的快照, 所以要考虑 3 秒内逐笔还原内有两笔不同方向的成交明细, 则分时成交快照取最后一笔的成交价并合集 3 秒内成交的手数之和. 这隐藏了另一个方向的撮合手数, 好在这中交易不多见(?).
全息数据是对成交数据的对应关系进行展示, 可以看大单小单流入流出. 数据要是能够完全反应主力,那么这样的指标就不存在.
问题: 东方财富的分时成交逐笔还原怎么看?
炒股票应该看远一点,分析题材和概念,盘口主要是感受买卖双方力量强弱。
综合来看, 分时成交数据里可能会有买卖方向不对的数据, 从逐笔还原数据中可以分析到精确的买卖净量. 不过这种不一致发生的数据量应当是比较小的, 所以可以假设分时成交数据仍然是正确的, 做数据分析时的近似交易明细.
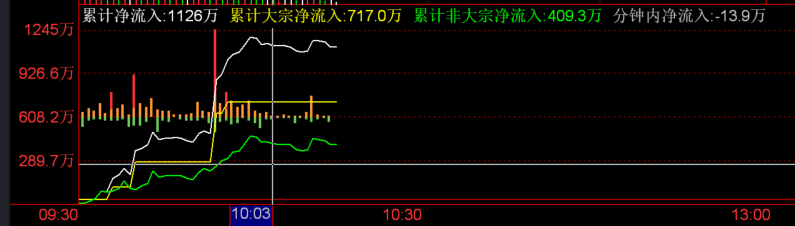
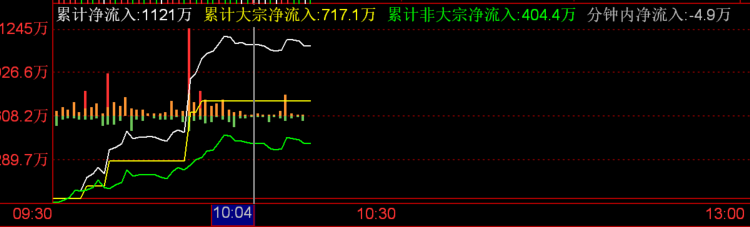
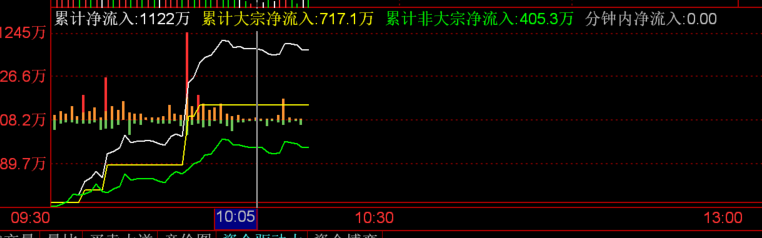
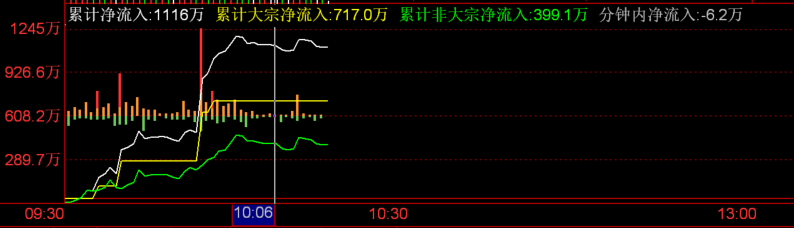
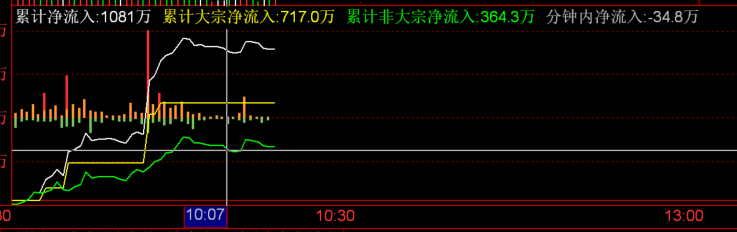
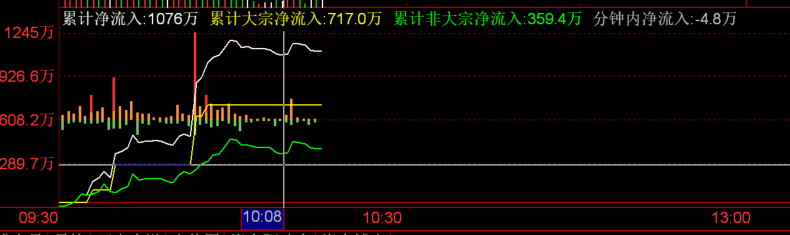
关于净流入 以下是从 10:03 分到 10:08 分的累计净流入数据.
累计净流入是按分钟计数的, 计算的结果是根据一分钟内主动买入花费的金额减去主动卖出获利的金额. 要看清这一点需要参考分时成交数据.
净主动买单和净主动卖单可能是不准确的, 因为分时成交的方向记录的撮合订单表中的最后一笔交易的方向, 如果最后一笔交易的方向订单量较少, 会导致此时的分时成交订单记录出现误差. 这个误差有时可以忽略不计(?)
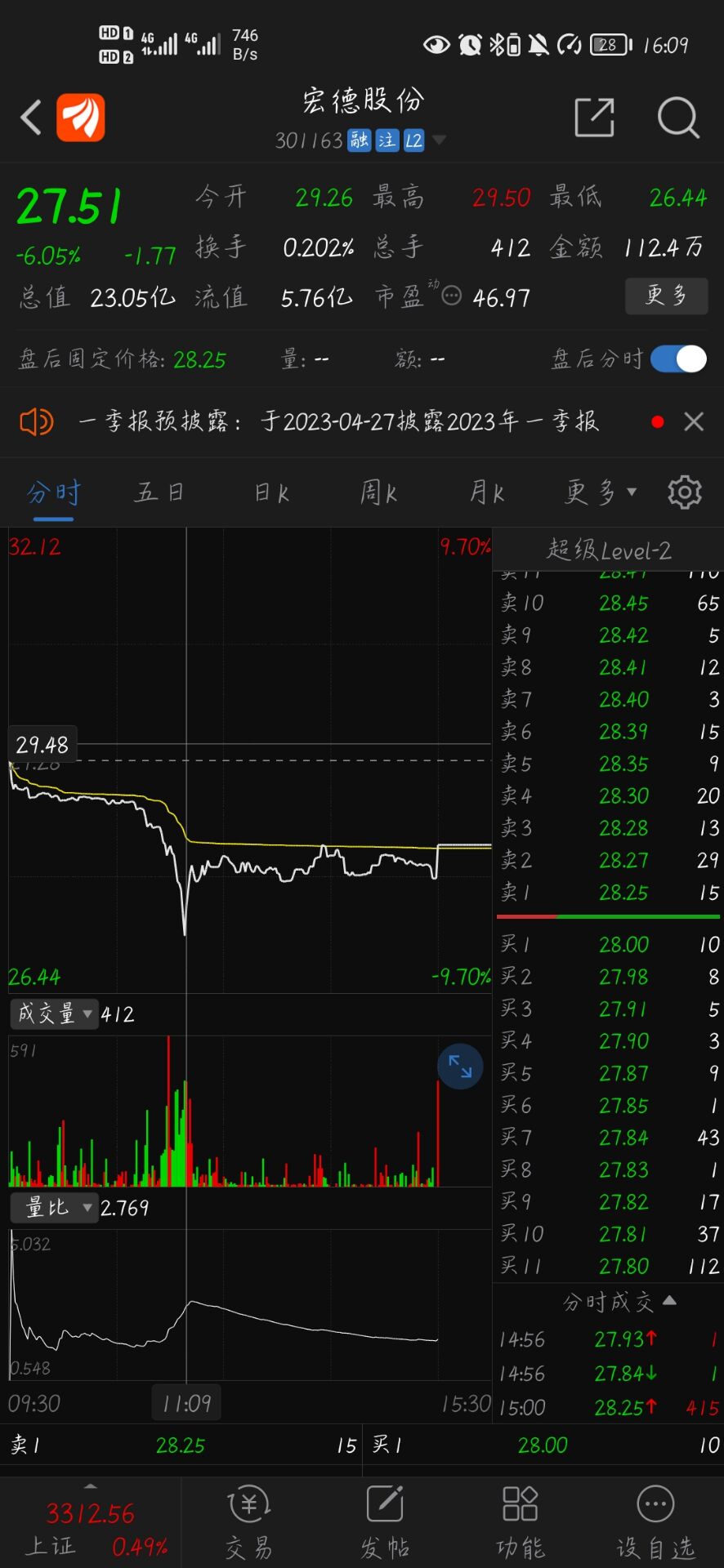
2023-04-04的观察记录 今天宏德股份(301163)盘中突然出现黄金坑, 所以觉得有必要研究其中的交易情况, 希望能从中发现交易模式上的总结.
当日的交易最低价为 26.44. 但是交易到 26.44 的委托价附近的委托非常稀缺导致主动成交单变化很奇怪.
上图左边是分时成交数据列表, 按照常识, 它是每三秒种的交易快照, 所以当交易快照期间交易价格过多时, 分时成交价选择为最后一笔的交易价格, 交易方向是与前一次快照收盘价比较确定的交易方向(这个要从下图才能看得出来, 从逐笔还原上来看, 成交手数 40, 38, 7, 2, 1 标记出的红色是当时交易的主动买盘行为, 尽管如此, 分时成交中的买卖方向依然使用与前一快照的收盘价比较后确定当前快照的买卖方向). 在下图中可以看到今天宏德股份的最低成交价为 26.44, 但很快后面的买盘将价格拉回到了正常水平, 但此时分时价格图还没有反应过来, 所以在 11:03 时没有出现黄金坑, 这里不分析买卖资金的意图, 单从分时图上看, 它后面的黄金坑是再次制造出来的另一个黄金坑.
分时成交数据的获取 以前从通达信的交易软件中获取过分时成交数据, 它也可以导出当日的成交明细. 但是上市的股票实在是太多了, 不可能做到人工全盘下载. 也试过读取离线下载的分钟线数据, 这在通达信的安装目录中使用二进制数据记录的, 很早一段时间网上有很多用 C 或 C++ 解码其中数据的代码和文章, 但不幸的是早年重装系统时没有留存其中的代码, 现在也不再重写那部分代码.
还有一段时间是用的新浪财经提供的 xls 数据, 但现在已经关闭了无法再次使用. 在前几个月又去查了下别的数据源获取途径, 现在使用 python 来获取股票的分时成交数据, 但是股价是未复权的, 需要注意. 代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 import datetimeimport itertoolsfrom pytdx.exhq import *from pytdx.hq import *from pathlib import PathSTOCK_CODE_FILE_PATH = "Y:/stockcodenames.txt" STOCK_DATA_DIR = "Y:/stock-data" if not os.path.exists(STOCK_DATA_DIR): os.mkdir(STOCK_DATA_DIR) api_hq = TdxHq_API() api_hq = api_hq.connect('119.147.212.81' , 7709 ) def get_all_trans_data (api, code, date ): start = 0 data = [] while True : part = api.get_history_transaction_data(TDXParams.MARKET_SZ, code, start, 888 , int (date)) if part is None : break data = part + data if len (part) < 888 : break start += 888 return data ''' 获取从start_date_str至今的所有分时成交数据, 按日期存在不同的文件中, 文件名用日期命名. start_date_str: 形如20220101的日期字符串 ''' def save_stock_data (start_date_str, stock_code ): if not os.path.exists(Path(STOCK_DATA_DIR, stock_code)): os.mkdir(Path(STOCK_DATA_DIR, stock_code)) start_time = datetime.datetime.strptime(start_date_str, "%Y%m%d" ) end_time = datetime.datetime.now() i = 0 next_time = start_time + datetime.timedelta(days=i) while next_time < end_time: print("正在处理股票: " + stock_code + ", 日期为" , next_time.strftime("%Y%m%d" ), "的数据" ) date_str = next_time.strftime("%Y%m%d" ) datas = get_all_trans_data(api_hq, stock_code, date_str) if len (datas) > 0 : with open (Path(STOCK_DATA_DIR, stock_code, date_str + '.txt' ), 'w' ) as f: for data in datas: f.write(',' .join([data['time' ].__str__(), data['price' ].__str__(), data['vol' ].__str__(), data['buyorsell' ].__str__()]) + '\n' ) i += 1 next_time = start_time + datetime.timedelta(days=i) with open (Path(STOCK_CODE_FILE_PATH), encoding='utf-8' ) as f: lines = f.readlines() for line in lines: stock_code = line.strip() print("=" * 50 , stock_code, "=" * 50 ) save_stock_data("20230113" , stock_code)
股票交易的简单统计 以下统计结果使用的数据是 上面代码获取到的所有股票的分时成交数据, 由于用 Mathematica 软件绘图编码我更熟悉, 所以以下代码都是 Mathematica 版本的.
中间函数的定义 1 2 3 4 5 6 7 8 9 10 11 StockExchangeAmount [ stockdatalist__ ] := Module [ { } , Total [ ToExpression [ stockdatalist [ [ All , 2 ] ] ] * ( 2 * ToExpression [ stockdatalist [ [ All , 4 ] ] ] - 1 ) * ToExpression [ stockdatalist [ [ All , 3 ] ] ] ] ] ;
一些常量 1 2 3 4 5 6 STOCKDATAMAINDIR = "Y:\\stock-data\\" ; STOCKACCDATA = "Y:\\stock-accumulation\\" ; STOCKCODEDIRS = FileNames [ "*" , STOCKDATAMAINDIR ] ;
模型1 每只股票每天的交易统计, 计算一天内总的交易笔数, 净买入额度, 净卖出额度和收盘价.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 Dynamic [ { STOCKCODE , datetime } ] ( STOCKCODE = FileBaseName [ # ] ; filename = FileNameJoin [ { "Y:\\stock-accumulation" , STOCKCODE <> ".txt" } ] ; STOCKDATEFILEPATH = FileNames [ "*" , # ] ; res = ( datetime = FileBaseName [ # ] ; stockdatastr = Import [ # ] ; stockdatalist = Partition [ StringSplit [ stockdatastr , { "\n" , "," } ] , 4 ] ; exchangeCount = Length [ stockdatalist ] ; lastprice = ToExpression [ stockdatalist [ [ - 1 , 2 ] ] ] ; exchangeAmount = StockExchangeAmount [ Select [ stockdatalist , # [ [ - 1 ] ] == "0" || # [ [ - 1 ] ] == "1" & ] ] ; { STOCKCODE , datetime , exchangeCount , exchangeAmount , lastprice } ) & /@ STOCKDATEFILEPATH ; Export [ filename , res ] ; ) & /@ STOCKCODEDIRS ;
返回的数据样本如下
模型2 最后价格表示每天的收盘价; 累计多空额度的解释是: 多方主买额度大一般对应价格上涨, 空方主卖额度大一般对应价格下跌.
计算 累计多空额度, 也就是主动买入额减去主动卖出额的累计值. 然后将每日收盘价 (最后价格) 按照比例贴在图标中. 做这个统计的目的是作为一种参考, 多空额度的下跌表示几天的净交易中, 卖出情绪比较积极, 长期主卖可能预示着股票跌入低谷. 反之, 买入情绪比较多, 容易达到顶部区域.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 filenames = FileNames [ "*.txt" , STOCKACCDATA ] ; Dynamic [ stockcode ] ( accumulatedata = ToExpression [ StringSplit [ Import [ # ] , "\n" ] ] ; exchangeAmount = accumulatedata [ [ All , 4 ] ] ; accumulateexchangeAmount = Accumulate [ exchangeAmount ] ; lastprice = accumulatedata [ [ All , 5 ] ] ; stockcode = FileBaseName [ # ] ; img = ListLinePlot [ { Rescale [ accumulateexchangeAmount , { Min [ accumulateexchangeAmount ] , Max [ accumulateexchangeAmount ] } , { Max [ lastprice ] , Min [ lastprice ] } ] , lastprice } , PlotStyle -> { Red , Blue } , PlotLabels -> { Style [ "累计多空额度" , 24 , Red ] , Style [ "最后价格" , 24 , Blue ] } , PlotTheme -> "Business" , ImageSize -> { 1920 , 1080 } , Filling -> { 1 -> { { 2 } , { Yellow , Orange } } } , FillingStyle -> Automatic , PlotLabel -> Style [ stockcode , 24 , Blue ] , PlotRange -> { Min [ lastprice ] , Max [ lastprice ] } ] ; Export [ "Y:\\stock-report\\" <> stockcode <> ".jpg" , img ] ) & /@ filenames ;
返回的数据样本如下
模型3 以下代码统计了5日内交易净额与交易笔数的走势. 需要注意收盘价达到谷底时的交易净额与交易笔数的增大时刻, 这有可能是大资金入场的隐秘操作.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 filenames = FileNames [ "*.txt" , STOCKACCDATA ] ; Dynamic [ stockcode ] Reap [ ( accumulatedata = ToExpression [ StringSplit [ Import [ # ] , "\n" ] ] ; stockcode = FileBaseName [ # ] ; exchangeCount = accumulatedata [ [ All , 3 ] ] ; lastprice = accumulatedata [ [ All , 5 ] ] ; exchangeAmount = accumulatedata [ [ All , 4 ] ] ; maprice = MovingAverage [ lastprice , 5 ] ; macount = MovingAverage [ exchangeCount , 5 ] ; If [ macount [ [ - 1 ] ] < 9 / 10 Min [ macount ] + 1 / 10 Max [ macount ] , Sow [ stockcode ] ] ; maamount = MovingAverage [ exchangeAmount , 5 ] ; img = ListLinePlot [ { Rescale [ macount , { Min [ macount ] , Max [ macount ] } , { Min [ maprice ] , Max [ maprice ] } ] , Rescale [ maamount , { Min [ maamount ] , Max [ maamount ] } , { Max [ maprice ] , Min [ maprice ] } ] , maprice } , PlotStyle -> { Red , Black , Blue } , PlotTheme -> "Business" , PlotLabels -> { Style [ "MA5交易总笔数" , 24 , Red ] , Style [ "MA5交易净额" , 24 , Black ] , Style [ "最后价格" , 24 , Blue ] } , PlotLabel -> Style [ stockcode , 24 , Blue ] , ImageSize -> { 1920 , 1080 } , PlotRange -> { Min [ lastprice ] , Max [ lastprice ] } ] ; Export [ "Y:\\stock-report2\\" <> stockcode <> ".jpg" , img ] ) & /@ filenames ; ]
返回的数据样本如下