事件与概率
定义: 在一定条件下, 必然发生或者必然不发生, 这种现象称为确定性现象. 必然会发生的现象称为必然现象. 必然不会发生的现象, 称为不可能现象.
在一定条件下, 并不总出现相同的结果, 但在大量重复试验中, 结果具有统计性规律的现象, 称为随机现象.
确定性现象的特征: 条件完全决定结果.
随机现象的特征: 条件不能完全决定结果.
定义: 对随机现象的观测或实验称为试验. 有以下特点:
- 试验可以在相同条件下重复进行;
- 试验的所有可能结果是事前已知且结果不止一种;
- 在每次试验中, 结果是事先无法确定的.
把有这三个特点的试验称为随机试验, 简称试验. 通常用字母$E$表示.
随机试验$E$的每一个可能的结果称为$E$的一个样本点, 一般用$\omega$表示.
$E$的所有样本点所组成的集合称为$E$的样本空间, 记为$\Omega$.
定义: 随机现象的结果称为随机事件, 简称事件.
关于事件, 要注意以下几点
- 任一事件是相应样本空间的一个子集;
- 事件发生当且仅当它所包含的某一样本点发生;
- 事件可以用集合表示, 也可以用文字语言表示, 甚至还可以用随机变量表示.
两个特殊的事件:
- 样本空间$\Omega$的最大子集, 称为必然事件.
- 样本空间$\Omega$的最小子集$\emptyset$, 称为不可能事件.
定义: 事件间的关系:
- 包含: 事件$A$发生必然导致事件$B$发生, 则称事件$B$包含事件$A$, 记为$A\subset B$.
- 相等: 若事件$A$与事件$B$中任一事件发生必然导致另一事件发生, 则称事件$A$与事件$B$相等, 记为$A=B$.
- 互不相容: 若事件$A$与事件$B$不能同时发生, 则称事件$A$与事件$B$是互不相容的(互斥的).
事件间的运算
- 并: 有限并, 可列并
- 交: 有限交, 可列交
- 差: “事件$A$发生而事件$B$不发生”, 称为事件$A$与事件$B$的差, 记为$A-B$.
- 必然事件$\Omega$对任一事件$A$的差$\Omega-A$称为事件$A$的对立事件, 记为$\overline{A}$.
事件的运算性质
- 交换律: $A\cup B=B\cup A$, $AB=BA$;
- 结合律: $(A\cup B)\cup C=A\cup(B\cup C)$, $(AB)C=A(BC)$;
- 分配率: $(A\cup B)\cap C=AC\cup BC$, $(A\cap B)\cup C=(A\cup C)\cap(B\cup C)$;
- 对偶律: $\overline{A\cup B}=\overline{A}\cap\overline{B}$, $\overline{A\cap B}=\overline{A}\cup\overline{B}$;
- $A-B=A-AB=A\overline{B}$.
定义: 在相同条件下, 进行$n$次试验, 在这$n$次试验中, 事件$A$发生的次数$m$称为事件$A$发生的频数, $\frac{m}{n}$称为事件$A$发生的频率, 记为$f_n(A)$. 当$n$相当大, 频率会接近一个常数, 把这个现象称为频率的稳定性. 通常, 当试验次数$n$逐渐增大时, 事件$A$出现的频率$f_n(A)$会接近一个常数, 把这个常数作为度量事件$A$发生可能性的大小, 并称为事件$A$的概率, 记为$P(A)$.
常取试验次数很大时事件的频率为概率的估计值, 称此概率为统计概率. 这种确定概率的方法称为频率方法.
概率的性质:
- $0\le P(A)\le1$;
- $P(\Omega)=1$, $P(\emptyset)=0$;
- 若$A_1,A_2,\cdots,A_k$是两两互不相容的事件, 则
- 由以上性质, 可以推出下列性质:
- $P(A)+P(\overline{A})=1$;
- 若$A\subset B$, 则$P(B-A)=P(B)-P(A)$;
- 对于任意的事件$A$与$B$, 有$P(B-A)=P(B)=P(AB)$;
- 对于任意的事件$A$与$B$, 有$P(A\cup B)=P(A)+P(B)-P(AB)$. 称为加法公式.
定义: 若一个随机试验有以下特点:
- 试验的样本空间$\Omega$包含有限个样本点;
- 试验中每个样本点发生的可能性是均等的.
则称此试验为古典概型试验.
在古典概型试验中, 若样本空间$\Omega$中样本点的个数为$n$, 事件$A$包含的样本点的个数为$k$, 则事件$A$的概率为$P(A)=\frac{k}{n}$.
二项分布(有放回抽样): 把$N$件产品编号, 其中有$n$件次品, 有放回地任取$m$次, 其中恰有$k$ ($k\le n$)件次品的概率为
符合这样的概率分布称为二项分布.
超几何分布(不放回抽样): 从$N$件产品中抽取$m$件产品, 总共有$n$件次品, 抽出恰好$k$件次品的概率为
这个概率称为超几何分布.
定义: 设一试验中事件 $A$ 发生的概率为 $P(A)$, 若又获得一些新的有关信息, 且可综合为事件 $B$, 这时在事件 $B$ 发生的条件下, 事件 $A$ 再发生的概率将会有所变化, 这种在新的条件下的概率称为条件概率, 记为 $P(A \mid B)$, 而 $P(A)$ 称为无条件概率.
设事件 $A, B$ 是样本空间 $\Omega$ 中的两个事件, 且 $P(B)>0$, 在事件 $B$ 发生的条件下, 事件 $A$ 发生的条件概率 $P(A \mid B)$ 定义为 $\frac{P(A B)}{P(B)}$, 即
其中 $P(A \mid B)$ 也称为给定事件 $B$ 下, 事件 $A$ 的条件概率.
条件概率的性质:
- $P(A \mid B) \ge 0$;
- $P(\Omega \mid B)=1$, $P(\emptyset \mid B)=0$;
- 若事件 $A_{1}, A_{2}, \cdots, A_{n}, \cdots$ 是两两互不相容的事件, 且 $P(B)>0$, 则
- $P(A \mid B)+P(\overline{A} \mid B)=1$
定义: 对任意两个事件 $A$ 与 $B$, 若
则称事件 $A$ 与 $B$ 相互独立, 或简称独立, 否则称事件 $A$ 与 $B$ 不独立或相关.
设有 $n$ 个事件 $A_{1}, A_{2}, \cdots, A_{n}$, 若对于任意的整数 $k$ ($1 \le k \le n$) 和任意的 $k$ 个整数 $i_{1}, i_{2}, \cdots, i_{k}$ ($1 \le i_{1}<i_{2}<\cdots<i_{k} \le n$), 有
则称 $A_{1}, A_{2}, \cdots, A_{n}$ 相互独立, 简称 $A_{1}, A_{2}, \cdots, A_{n}$ 独立.
定义: 若试验满足下列条件:
(1) 每次试验只有两种可能结果 $A, \overline{A}$;
(2) $A$ 在每次的试验中出现的概率 $p$ 保持不变;
(3) 各次试验是相互独立的;
(4) 共进行 $n$ 次试验,
则称这种试验为 $n$ 重伯努利试验.
随机变量及其分布
定义: 定义在样本空间 $\Omega$ 上, 取值于实数域 $\RR$, 若对于样本空间的任意一个样本点 $\omega$, 都有唯一的实数 $X(\omega)$ 与之对应, 则称 $X(\omega)$ 为随机变量, 常用大写字母 $X, Y, Z$ 等表示. 用小写字母表示随机变量的取值.
定义: 如果随机变量 $X(\omega)$ 所有可能取值是有限个或可列多个, 则称 $X(\omega)$ 为离散型随机变量.
设 $X$ 是离散型随机变量, 它的所有可能取值是 $x_{1}, x_{2}, \cdots$. 假如 $X$ 取 $x_{i}$ 的概率为 $P(X=x_{i})=p_{i}$, $i=1,2, \cdots$, 且满足
(1) $p_{i} \ge 0$, $i=1,2, \cdots$;
(2) $\sum_{i=1}^{\infty} p_{i}=1$,
则称 $\{p_{i}\}$ 为随机变量 $X$ 的分布列(概率分布), 也可以表示为
| $X$ |
$x_{1}$ |
$x_{2}$ |
$\cdots$ |
$x_{n}$ |
$\cdots$ |
| $P$ |
$p_{1}$ |
$p_{2}$ |
$\cdots$ |
$p_{n}$ |
$\cdots$ |
几种常见的离散型随机变量的概率分布
定义: 0-1 分布 (两点分布)
设随机变量 $X$ 只可能取 0 和 1 两个值, 且取各值的概率是
则称 $X$ 服从两点分布, 记为 $X \sim B(1, p)$, 也可以写成
| $X$ |
$0$ |
$1$ |
| $P$ |
$1-p$ |
$p$ |
二项分布
设随机变量 $X$ 的所有可能取值为 $0,1, \cdots, n$, 且取各值的概率为 $P(X=k)=C_{n}^{k} p^{k}(1-p)^{n-k}$, $k=0,1, \cdots, n$ ($0<p<1$),
则称 $X$ 服从参数为 $n, p$ 的二项分布, 记为 $X \sim B(n, p)$.
特别地, 当 $n=1$ 时, 二项分布 $X \sim B(1, p)$, 即为 $0-1$ 分布.
泊松分布
设随机变量 $X$ 所有可能取值为 $0,1,2, \cdots$, 且它取各值的概率为
则称 $X$ 服从参数为 $\lambda$ 的泊松分布, 记为 $X \sim P(\lambda)$.
随机变量的分布函数
定义: 设 $X$ 是一个随机变量, 对任意实数 $x$, 函数
称为 $X$ 的分布函数.
已知 $\{p_{k}\}$ 是离散型随机变量 $X$ 的分布列, 则可以求出随机变量 $X$ 的分布函数, 以及随机变量在某区间的概率:
(1) 随机变量 $X$ 的分布函数:
(2) 随机事件 $\{a<X \le b\}$ 的概率:
定义: 设 $X$ 是随机变量, $f(x)$ 是定义在整个实数轴上的一个函数, 且满足下列条件:
(1) $f(x) \ge 0$;
(2) $\int_{-\infty}^{+\infty} f(x) \mathrm{d} x=1$;
(3) $P(a \le X \le b)=\int_{a}^{b} f(x) \mathrm{d} x$,
则称 $X$ 是连续型随机变暈, $f(x)$ 称为 $X$ 的概率分布(概率密度函数或密度函数).
(i) 上述定义中的前两个条件是判定一个函数是否为连续型随机变量的概率密度函数的充要条件.
(ii) $X$ 落入区间 $[a, b]$ 内的概率为密度函数在该区间的积分.
(iii) 连续型随机变量 $X$ 仅取一点的概率均为零, 即
在概率论中, 概率为零的事件称为零概率事件, 它与不可能事件 $\varnothing$ 是有差别的, 同样, 概率为 1 的事件与必然事件也是有差别的.
(iv) 连续型随机变量 $X$ 取值落在区间的概率与区间的开闭无关.
(v) 密度函数 $f(x)$ 在某点处的数值并不能反映随机变量在该值处的概率, 但能反映随机变量在该值附近处的概率的大小(严格来说这一小句是需要条件的, 比如要求$f(x)$在这一点附近连续), 这里如果把概率理解为质量, 则 $f(x)$ 相当于密度.
(vi) $F(x)=P(X \le x)=P(-\infty<X \le x)=\int_{-\infty}^{x} f(x) \mathrm{d} x$, 若 $f(x)$ 是可积函数, 则分布函数 $F(x)$ 一定是连续函数; 若 $f(x)$ 在 $x$ 处连续, 则 $F(x)$ 在 $x$ 处可导且 $F^{\prime}(x)=f(x)$.
定义: 均匀分布
若连续型随机变量 $X$ 的概率密度函数为
则称 $X$ 在区间 $[a, b]$ 上服从均匀分布, 记为 $X \sim U[a, b]$. 其相应的分布函数为
指数分布
若连续型随机变量 $X$ 的概率密度函数为
其中 $\lambda>0$ 为常数, 则称 $X$ 服从参数为 $\lambda$ 的指数分布, 记为 $X \sim E(\lambda)$. 其相应的分布函数为
正态分布
若连续型随机变量 $X$ 的概率密度函数为
其中 $\mu, \sigma$ ($\sigma>0$) 为常数, 则称 $X$ 服从参数为 $\mu, \sigma$ 的正态分布或高斯分布, 记为 $X \sim N(\mu, \sigma^{2})$.
定义: 设有函数 $Y=g(X)$, 其定义域为随机变量 $X$ 的一切可能取值构成的集合. 如果对于 $X$ 的每一个可能取值 $x$, 另一个随机变量 $Y$ 相应的取值为 $y=g(x)$, 则称 $Y$ 为随机变量 $X$ 的函数, 记为 $Y=g(X)$.
若 $X$ 是离散型随机变量, 则 $Y=g(X)$ 也是一个离散型随机变量, $g(X)$ 的分布可由 $X$ 的分布直接求出. 设 $X$ 的概率分布为
| $X$ |
$x_1$ |
$x_2$ |
$\cdots$ |
$x_n$ |
$\cdots$ |
| $P(X=x_i)$ |
$p_1$ |
$p_2$ |
$\cdots$ |
$p_n$ |
$\cdots$ |
则 $Y=g(X)$ 的概率分布为
| $Y$ |
$g(x_1)$ |
$g(x_2)$ |
$\cdots$ |
$g(x_n)$ |
$\cdots$ |
| $P(Y=y_i)$ |
$p_1$ |
$p_2$ |
$\cdots$ |
$p_n$ |
$\cdots$ |
若 $g(x_{i})$ 的值中有相等的, 那么就把那些相等的值分别合并, 并根据概率加法公式将相应的概率相加, 便得到 $Y$ 的分布.
多维随机变量及其分布
定义: 多维随机变量
设随机变量 $X_{1}(\omega), X_{2}(\omega), \cdots, X_{n}(\omega)$ 定义在同一样本空间 $\Omega$ 上. 若对于样本空间的任一个样本点 $\omega$, 都有确定的 $n$ 个实数与之对应, 则称 $\boldsymbol{X}(\omega)=(X_{1}(\omega), X_{2}(\omega), \cdots, X_{n}(\omega))$ 为 $n$ 维随机变量 .
二维离散型随机变量
假如随机变量 $(X, Y)$ 的每个分量都是一维离散型随机变量, 则称 $(X, Y)$ 为二维离散型随机变量. 若设 $\{x_{n}\}$ 与 $\{y_{n}\}$ 分别为 $X$ 与 $Y$ 的全部可能取值, 则概率
全体称为 $(X, Y)$ 的联合概率分布.
多维随机变量的联合分布
设 $\boldsymbol{X}=(X_{1}, X_{2}, \cdots, X_{n})$ 是 $n$ 维随机变量. 对任意 $n$ 个实数 $x_{1}, x_{2}, \cdots, x_{n}$ 所组成的 $n$ 个事件 “$X_{1} \leqslant x_{1}$”, “$X_{2} \leqslant x_{2}$”, $\cdots$, “$X_{n} \leqslant x_{n}$” 同时发生的概率
称为 $n$ 维随机变量 $\boldsymbol{X}$ 的联合分布函数.
二维连续型随机变量
设二维随机变量 $(X, Y)$ 的联合分布函数为 $F(x, y)$. 假如各分量 $X$ 和 $Y$ 都是一维连续型随机变量, 并对于任意实数 $x$ 与 $y$, 若存在一个二元非负函数 $f(x, y)$, 使
则称 $(X, Y)$ 为二维连续型随机变量, $f(x, y)$ 称为 $(X, Y)$ 的联合概率密度函数.
$(X, Y)$ 的两个边际分布函数分别为
$(X, Y)$ 关于 $X$ 和 $Y$ 的边际密度函数分别为
随机变量间的独立性
设 $(X_{1}, X_{2}, \cdots, X_{n})$ 是 $n$ 维随机变量. 若对任意 $n$ 个实数 $x_{1}$, $x_{2}, \cdots, x_{n}$ 所组成的 $n$ 个事件 “$X_{1} \leqslant x_{1}$”, “$X_{2} \leqslant x_{2}$”, $\cdots$, “$X_{n} \leqslant x_{n}$” 相互独立, 即有
或
则称 $n$ 个随机变量 $X_{1}, X_{2}, \cdots, X_{n}$ 相互独立, 否则称 $X_{1}, X_{2}, \cdots, X_{n}$ 不相互独立.
随机变量的数字特征
定义: 离散型随机变量的数学期望
设离散型随机变量 $X$ 的分布列为 $P(X=x_{i})=p_{i}$, $i=1,2, \cdots$.
若级数 $\sum_{i=1}^{\infty} x_{i} p_{i}$ 绝对收敛, 即 $\sum_{i=1}^{\infty}|x_{i}| p_{i}<+\infty$, 则称随机变量 $X$ 的数学期望存在且该级数之和为 $X$ 的数学期望, 或简称为期望, 记为 $E(X)$, 即
若级数 $\sum_{i=1}^{\infty} x_{i} p_{i}$ 不绝对收敛, 则该随机变量 $X$ 的数学期望不存在.
连续型随机变量的数学期望
设连续型随机变量 $X$ 的密度函数为 $f(x)$. 若积分 $\int_{-\infty}^{+\infty} x f(x) \mathrm{d} x$ 绝对收㪉, 即 $\int_{-\infty}^{+\infty}|x| f(x) \mathrm{d} x<\infty$, 则称 $\int_{-\infty}^{+\infty} x f(x) \mathrm{d} x$ 的值为随机变量 $X$ 的数学期望, 记为 $E(X)$, 即
随机变量的数学期望可能不存在. 比如Cauchy分布, $f(x)=\frac1{\pi}\cdot\frac1{1+x^2}$.
数学期望的性质
常数$C$的数学期望等于$C$, 即$E(C)=C$;
常数 $C$ 可以移到数学期望运算符号外面来, 即 $E(C X)=C E(X)$;
随机变量和的期望等于期望的和,即 $E(X+Y)=E(X)+E(Y)$;
期望具有线性性质, 即
方差与标准差
定义: 设 $X$ 是随机变量. 若 $E(X-E(X))^{2}$ 存在, 则称 $E(X-E(X))^{2}$ 为 $X$ 的方差, 记为 $D(X)$ 或 $\mathrm{Var}(X)$, 即
而$\sqrt{D(X)}$称为$X$的标准差或均方差, 记为$\sigma(X)$.
方差的性质:
- 常数 $C$ 的方差等于零, 即 $D(C)=0$;
- 常数 $C$ 可以平方后移到方差运算符号外面来, 即
- 对任意常数 $C$ 和随机变量 $X$, 有 $D(X+C)=D(X)$;
- 对任意的常数 $a, b$ 和随机变量 $X$, 有 $D(a X+b)=a^{2} D(X)$;
- 相互独立的随机变量和或差的方差等于方差的和, 即
数理统计的基本概念
定义: 一个数理统计问题中总有它明确的研究对象, 我们将研究对象的全体称为总体 (母体), 而把组成总体的每个成员称为个体.
总体中所包含个体的数目称为总体容量. 按照总体容量是有限还是无限将总体分为有限总体或无限总体.
总体是一个具有特定分布的随机变量, 研究总体的分布及其数字特征, 常用的有两种方法:
- 普查: 对总体中的每个个体进行检查或观察.
- 抽样: 从总体中抽取部分个体进行检查或观察, 然后根据抽样观察所得到的数据对总体进行推断.
从总体$X$中抽出的部分个体组成的集合称为样本, 组成样本的个体称为样品, 一个样本中所含样品的个数称为样本容量. 样本的观察值简称样本值.
抽样时应避免人为干扰, 在统计学中, 最常用的一种抽样方法是”简单随机抽样”, 它对抽样有如下两点要求:
(1) 代表性: 总体的每一个体有同等机会被选入样本;
(2) 独立性: 样品 $X_{1}, X_{2}, \cdots, X_{n}$ 是相互独立的随机变量.
这样得到的样本称为独立同分布的样本, 又称为简单随机样本.
统计量与抽样分布
定义: 设 $(X_{1}, X_{2}, \cdots, X_{n})$ 是来自总体 $X$ 的一个样本, $g(X_{1}, X_{2}, \cdots, X_{n})$ 是样本函数, 且 $g$ 中不含有任何末知参数, 则称 $g(X_{1}, X_{2}, \cdots, X_{n})$ 是一个统计量.
由于样本是随机变量, 而统计量是样本的函数, 故统计量是随机变量的函数, 也就是说统计量$g(X_1,X_2,\cdots,X_n)$也是随机变量, 将统计量的分布称为抽样分布. 统计量中可以含有参数, 但不能含有未知参数.
设 $(X_{1}, X_{2}, \cdots, X_{n})$ 是来自总体 $X$ 的一个样本, $(x_{1}, x_{2}, \cdots, x_{n})$ 是该样本的观察值, 定义以下统计量:
样本平均值(均值) $\overline{X}=\frac{1}{n} \sum_{i=1}^{n} X_{i}$;
样本方差 $S^{2}=\frac{1}{n-1} \sum_{i=1}^{n}(X_{i}-\overline{X})^{2}=\frac{1}{n-1}\left(\sum_{i=1}^{n} X_{i}^{2}-n \overline{X}^{2}\right)$;
样本标准差
样本 $k$ 阶 (原点) 矩 $A_{k}=\frac{1}{n} \sum_{i=1}^{n} X_{i}^{k}$, ($k=1,2, \cdots$);
样本 $k$ 阶中心矩 $B_{k}=\frac{1}{n} \sum_{i=1}^{n}(X_{i}-\overline{X})^{k}$, ($k=1,2, \cdots$).
它们的观察值分别为
这些观察值分别称为样本均值, 样本方差, 样本标准差, 样本$k$阶(原点)矩, 样本$k$阶中心距. 以上这些统计量统称为样本矩.
设总体 $X$ 的分布函数为 $F(x)$, 类似定义总体的 $k$ 阶(原点) 矩, $k$ 阶中心矩 (假设其存在) 如下:
将其统称为总体矩.
三大抽样分布
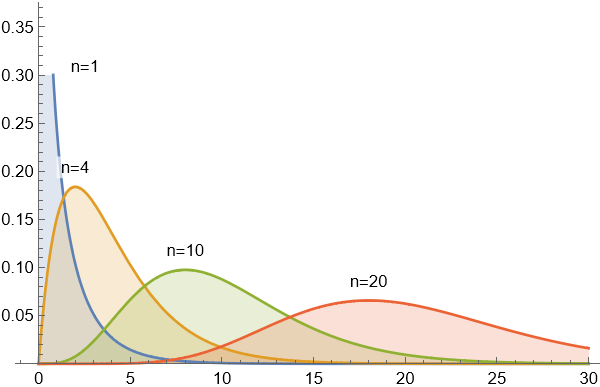
定义: $\chi^{2}$ 分布
设 $(X_{1}, X_{2}, \cdots, X_{n})$ 是来自总体 $X \sim N(0,1)$ 的一个样本, 则称统计量
服从自由度为 $n$ 的 $\chi^{2}$ 分布, 记为 $\chi^{2} \sim \chi^{2}(n)$. 这里自由度 $n$ 指的是独立随机变量的个数.
$\chi^{2}(n)$ 分布的概率密度函数为
其中 $\Gamma(s)$ 是 $\Gamma$ 函数, 定义 $\Gamma(s)=\int_{0}^{+\infty} x^{s-1} \mathrm{e}^{-x} \mathrm{d} x$.
1
2
3
4
| Plot[Table[
PDF[ChiSquareDistribution[\[Nu]], x], {\[Nu], {1, 4, 10, 20}}] //
Evaluate, {x, 0, 30}, Filling -> Axis, PlotRange -> {0, 0.3},
PlotLabels -> Placed[{"n=1", "n=4", "n=10", "n=20"}, {Above}]]
|
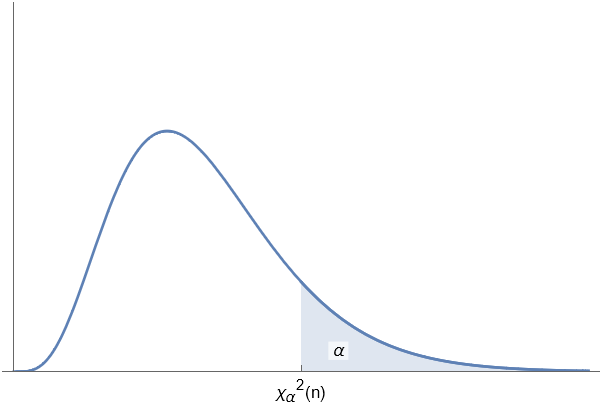
若随机变量 $\chi^{2} \sim \chi^{2}(n)$, 对于给定的正数 $\alpha$ ($0<\alpha<1$), 称满足条件
的点 $\chi_{\alpha}^{2}(n)$ 为 $\chi^{2}(n)$ 分布的上 $\alpha$ 分位点.
1
2
3
4
5
6
7
8
| Show[Plot[PDF[ChiSquareDistribution[10], x] // Evaluate, {x, 0, 30},
PlotRange -> {0, 0.15}],
Plot[PDF[ChiSquareDistribution[10], x] // Evaluate, {x, 15, 30},
Filling -> Axis, PlotRange -> {0, 0.15},
PlotLabels -> Placed["\[Alpha]", {Right, {13, 0}}]],
Ticks -> {{{15,
"\!\(\*SuperscriptBox[SubscriptBox[\(\[Chi]\), \(\[Alpha]\)], \
\(2\)]\)(n)"}}, None}]
|
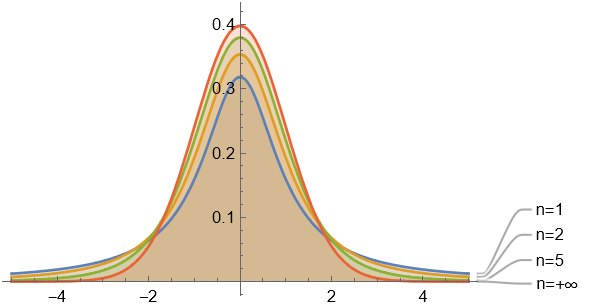
定义: $t$ 分布
设 $X \sim N(0,1)$, $Y \sim \chi^{2}(n)$, 且 $X$ 与 $Y$ 相互独立, 则称随机变量
服从自由度为 $n$ 的 $t$ 分布, 记为 $T \sim t(n)$.
$t$ 分布又称为学生氏 (student) 分布, $t$ 分布的概率密度函数为
1
2
3
4
| Plot[Table[
PDF[StudentTDistribution[\[Nu]], x], {\[Nu], {1, 2, 5, 100}}] //
Evaluate, {x, -5, 5}, Filling -> Axis,
PlotLabels -> {"n=1", "n=2", "n=5", "n=+\[Infinity]"}]
|
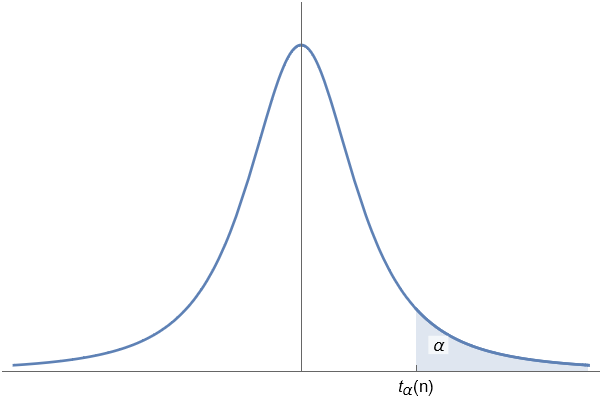
若随机变量 $T \sim t(n)$, 对于给定的正数 $\alpha$ ($0<\alpha<1$), 称满足条件
的点$t_{\alpha}(n)$为$t$分布的上$\alpha$分位点.
1
2
3
4
5
6
7
| Show[Plot[PDF[StudentTDistribution[2], x] // Evaluate, {x, -5, 5},
PlotRange -> {0, 0.4}],
Plot[PDF[StudentTDistribution[2], x] // Evaluate, {x, 2, 5},
Filling -> Axis, PlotRange -> {0, 0.4},
PlotLabels -> Placed["\[Alpha]", {Right, {8, 0}}]],
Ticks -> {{{2, "\!\(\*SubscriptBox[\(t\), \(\[Alpha]\)]\)(n)"}},
None}]
|
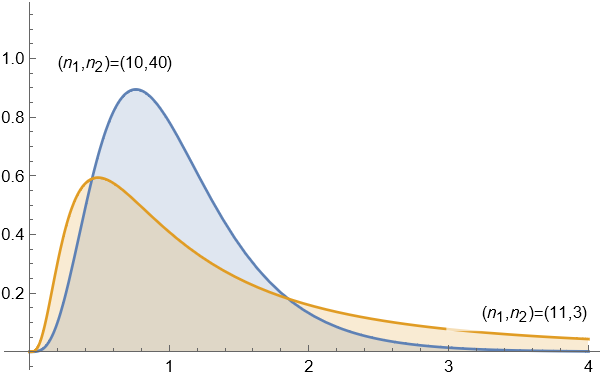
定义: $F$ 分布
设 $X \sim \chi^{2}(n_{1})$, $Y \sim \chi^{2}(n_{2})$, 且 $X$ 与 $Y$ 相互独立, 则称随机变量
服从第一自由度为 $n_{1}$, 第二自由度为 $n_{2}$ 的 $F$ 分布, 记为 $F \sim F(n_{1}, n_{2})$.
$F$ 分布的概率密度函数为
1
2
3
4
5
6
7
8
| Plot[{PDF[FRatioDistribution[10, 40], x],
PDF[FRatioDistribution[11, 3], x]} // Evaluate, {x, 0, 4},
Filling -> Axis,
PlotLabels ->
Placed[{"(\!\(\*SubscriptBox[\(n\), \(1\)]\),\!\(\*SubscriptBox[\(n\
\), \(2\)]\))=(10,40)",
"(\!\(\*SubscriptBox[\(n\), \(1\)]\),\!\(\*SubscriptBox[\(n\), \
\(2\)]\))=(11,3)"}, {Above, Right}]]
|
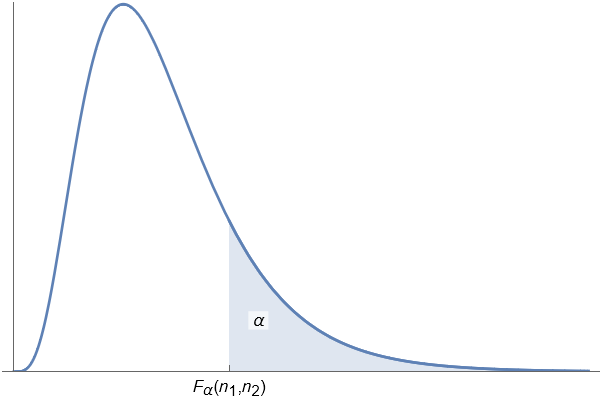
若随机变量 $F \sim F(n_{1}, n_{2})$, 对于给定的正数 $\alpha$ ($0<\alpha<1$), 称满足条件
的点 $F_{\alpha}(n_{1}, n_{2})$ 为 $F(n_{1}, n_{2})$ 分布的上 $\alpha$ 分位点.
1
2
3
4
5
6
7
8
9
| Show[Plot[PDF[FRatioDistribution[10, 40], x] // Evaluate, {x, 0, 4},
PlotRange -> {0, 0.9}],
Plot[PDF[FRatioDistribution[10, 40], x] // Evaluate, {x, 1.5, 4},
Filling -> Axis, PlotRange -> {0, 0.4},
PlotLabels -> Placed["\[Alpha]", {Right, {17, -2}}]],
Ticks -> {{{1.5,
"\!\(\*SubscriptBox[\(F\), \
\(\[Alpha]\)]\)(\!\(\*SubscriptBox[\(n\), \
\(1\)]\),\!\(\*SubscriptBox[\(n\), \(2\)]\))"}}, None}]
|
参数估计
参数的点估计
定义: 设总体 $X$ 的分布函数已知, 但其中有一个或多个未知参数 $\theta$, 借助于总体 $X$ 的一组样本 $X_{1}, X_{2}, \cdots, X_{n}$, 构造一个适当的统计量 $\widehat{\theta}(X_{1}, X_{2}, \cdots, X_{n})$ 来估计总体未知参数的问题称为点估计问题. $\widehat{\theta}(X_{1}, X_{2}, \cdots, X_{n})$ 称为未知参数 $\theta$ 的估计量, 用它的观察值 $\widehat{\theta}(x_{1}, x_{2}, \cdots, x_{n})$ 作为未知参数 $\theta$ 的估计值. 估计量和估计值统称为估计, 并简记为 $\widehat{\theta}$. 但必须注意, 对于样本的不同观察值, 估计值是不同的.
矩估计法
定义: 矩估计法是基于一种简单的”替换”思想建立起来的估计方法, 因为样本矩依概率收敛于相应的总体距, 样本矩的连续函数依概率收敛于相应的总体距的连续函数.
基本思想是用样本矩估计相应的总体距, 用样本矩的连续函数估计相应的总体距的连续函数, 从而得出参数估计, 这种方法称为矩估计法.
若总体 $X$ 的分布 $F(X, \theta)$ 已知, 但分布函数中有 $k$ 个未知参数 $\theta_{1}, \theta_{2}, \cdots, \theta_{k}$, 设总体 $X$ 的前 $k$ 阶矩存在, 则矩估计法的具体步骤如下:
(1) 求出 $\mu_{l}=E(X^{l})=\mu(\theta_{1}, \theta_{2}, \cdots, \theta_{k})$, $l=1,2, \cdots, k$.
(2) 令 $\mu_{l}=A_{l}$, $A_{l}=\frac{1}{n} \sum_{i=1}^{n} X_{i}^{l}$, $l=1,2, \cdots, k$, 这是一个包含 $k$ 个未知数 $\theta_{1}, \theta_{2}, \cdots, \theta_{k}$ 的 $k$ 个方程组成的方程组.
(3) 解出其中的 $\theta_{1}, \theta_{2}, \cdots, \theta_{k}$, 用 $\widehat{\theta}_{1}, \widehat{\theta}_{2}, \cdots, \widehat{\theta}_{k}$ 表示.
(4) 用方程组的 $\widehat{\theta}_{1}, \widehat{\theta}_{2}, \cdots, \widehat{\theta}_{k}$ 分别作为 $\theta_{1}, \theta_{2}, \cdots, \theta_{k}$ 的估计量, 这个估计量称为矩估计量.
极大似然估计
定义: 当总体分布类型已知时, 矩估计法未能充分利用总体分布提供的信息, 这时常考虑用极大似然估计, 极大似然估计常用 MLE 缩写, 它是利用总体的分布密度或者概率分布的表达式及其样本所提供的信息求未知参数的估计量.
若总体 $X$ 为离散型, 其概率分布为
其中 $\theta$ 为未知参数, 从总体中抽取样本容量为 $n$ 的样本 $(X_{1}, X_{2}, \cdots, X_{n})$ 的一组观察值为 $(x_{1}, x_{2}, \cdots, x_{n})$, 则 $(X_{1}, X_{2}, \cdots, X_{n})$ 的联合分布律为
易知样本 $X_{1}, X_{2}, \cdots, X_{n}$ 取到观察值 $x_{1}, x_{2}, \cdots, x_{n}$ 的概率为 $\prod_{i=1}^{n} p(x_{i}; \theta)$, 定义似然函数为
这是一组观察值为 $(x_{1}, x_{2}, \cdots, x_{n})$ 的概率. 现在就是寻找这样的一组观察值 $(x_{1}, x_{2}, \cdots, x_{n})$ 的函数 $\widehat{\theta}=\widehat{\theta}(x_{1}, x_{2}, \cdots, x_{n})$, 使似然函数
则 $\widehat{\theta}(x_{1}, x_{2}, \cdots, x_{n})$ 称为参数 $\theta$ 的极大似然估计值, 其相应的统计量 $\widehat{\theta}(X_{1}, X_{2}, \cdots, X_{n})$ 称为 $\theta$ 的极大似然估计量.
若总体 $X$ 为连续型, 其概率密度函数为 $f(x; \theta)$, 其中 $\theta$ 为未知参数, 同样定义似然函数为
若 $\widehat{\theta}(X_{1}, X_{2}, \cdots, X_{n})$ 使得
则 $\widehat{\theta}(x_{1}, x_{2}, \cdots, x_{n})$ 称为参数 $\theta$ 的极大似然估计值, 其相应的统计量 $\widehat{\theta}(X_{1}, X_{2}, \cdots, X_{n})$ 称为 $\theta$ 的极大似然估计量.
对点估计量的评价
定义: 衡量点估计量好坏的标准: 无偏性, 有效性, 一致性.
设 $\widehat{\theta}=\widehat{\theta}(X_{1}, X_{2}, \cdots, X_{n})$ 是未知参数 $\theta$ 的点估计量, 若
则称 $\widehat{\theta}$ 是 $\theta$ 的无偏估计, 否则称为有偏估计.
设 $\widehat{\theta}_{1}=\widehat{\theta}_{1}(X_{1}, X_{2}, \cdots, X_{n})$, $\widehat{\theta}_{2}=\widehat{\theta}_{2}(X_{1}, X_{2}, \cdots, X_{n})$ 是未知参数 $\theta$ 的无偏估计量. 若 $D(\widehat{\theta}_{1}) \leqslant D(\widehat{\theta}_{2})$, 则称 $\widehat{\theta}_{1}$ 比 $\widehat{\theta}_{2}$ 有效.
设对每个自然数 $n$, $\widehat{\theta}_{n}=\widehat{\theta}_{n}(X_{1}, X_{2}, \cdots, X_{n})$ 都是未知参数 $\theta$ 的估计量. 如果对任意的 $\varepsilon>0$, 都有
则称 $\widehat{\theta}_{n}$ 是 $\theta$ 的相合估计量(一致估计量).
参数的区间估计
置信区间的概念
定义: 设 $X_{1}, X_{2}, \cdots, X_{n}$ 是来自总体 $X \sim F(X; \theta)$ 的一个样本, $\theta$ 为未知参数. 若对给定的 $\alpha$($0<\alpha<1$), 存在两个统计量 $\widehat{\theta}_{1}=\widehat{\theta}_{1}(X_{1}, X_{2}, \cdots, X_{n})$ 与 $\widehat{\theta}_{2}=\widehat{\theta}_{2}(X_{1}, X_{2}, \cdots, X_{n})$, 对所有 $\theta$ 的可能取值均有
则称随机区间 $(\widehat{\theta}_{1}, \widehat{\theta}_{2})$ 为参数 $\theta$ 的置信度为 $1-\alpha$ 的置信区间, $\widehat{\theta}_{1}$ 与 $\widehat{\theta}_{2}$ 分别称为 $1-\alpha$ 的置信下限与置信上限, 置信度 $1-\alpha$ 也称为置信水平.
参数 $\theta$ 是一个常数, 没有随机性, 区间 $(\widehat{\theta}_{1}, \widehat{\theta}_{2})$ 是随机的.
置信水平 $1-\alpha$ 的含义是: 随机区间 $(\widehat{\theta}_{1}, \widehat{\theta}_{2})$ 以 $1-\alpha$ 的概率包含着参数 $\theta$ 的真实值, 而不能说参数 $\theta$ 以 $1-\alpha$ 的概率落人随机区间 $(\widehat{\theta}_{1}, \widehat{\theta}_{2})$.
参考资料: 马丽杰, 明杰秀, 线性代数与概率统计.










